Ладно, загадка Жана Фреско. У вас есть таблица, скажем, на 50 тысяч строк. Как прочитать из неё полмиллиарда?
Раз плюнуть, Nested Loops + Clustered Index Seek:
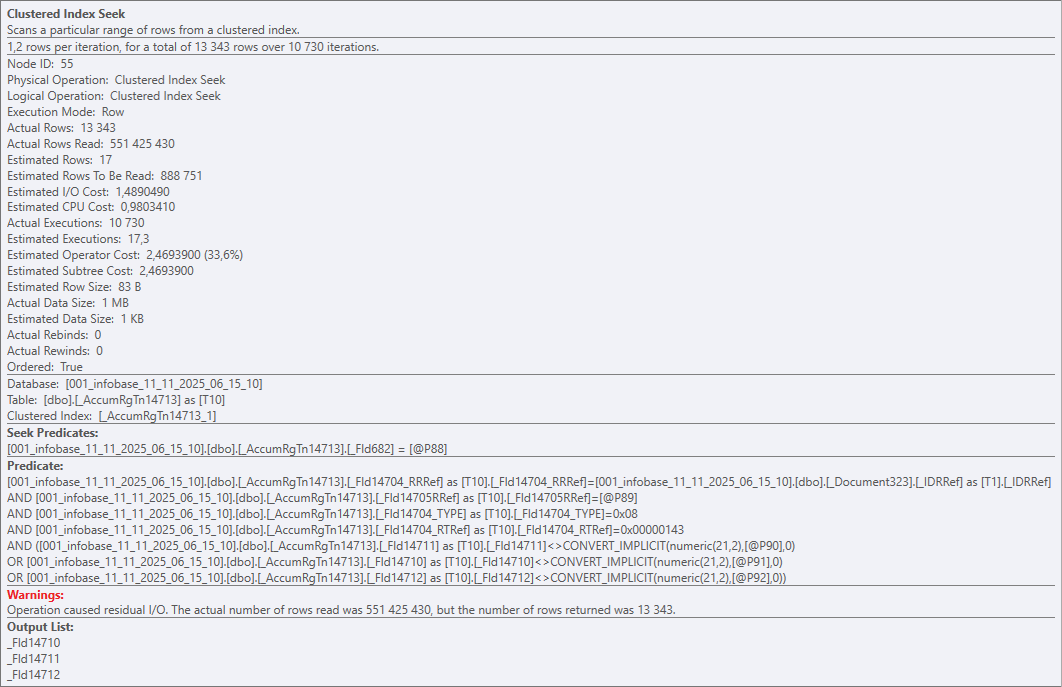
От Clustered Index Seek тут одно название, конечно. Фактически оператор при каждом исполнении пробегает по всей таблице (всему кластерному индексу) и сверяет каждую запись с Predicates. И так — 10 730 раз для 51 391 записей. В итоге 551 425 430 строк прочитали, 13 343 вернули.

Короче, идеальный пример плохого плана запроса в вакууме, хоть сейчас тащи в палату мер и весов. Nested Loops, если кто позабыл, работает примерно так:
For Each Table1Row In Table1 Do
For Each Table2Row In Table2 Do
...
Это ОК для мелких таблиц, но СУБД может его применить и для таблиц поболбше — например, если ей не хватает времени на построение плана.
Это и произошло в нашем случае. Прыгнем повыше, на уровень платформы: тут у нас динамический список с запросом по таблице документа, к которой разработчики прицепили с десяток виртуальных таблиц регистров накопления.
Некоторые регистры и сами по себе были здоровенными, а виртуальные таблицы дополнительно поддали жару (каждая превращается в 2+ вложенных запроса). СУБД честно пыталась придумать эффективный алгоритм, но в какой-то момент решала, что хреновый план запроса всё же лучше, чем вообще никакого.
В итоге пользователь что? Пытался поискать документ по номеру и клиентское приложение просто-напросто зависало.
Короче, по поводу виртуальных таблиц в динамических списках. В английском есть выражение «desire path», «протоптанная дорожка». Часто прицепить виртуальную таблицу к основной — и в самом деле самый простой, быстрый и привычный способ решить задачу. Но он не эффективен.
Есть, например, обработчик ПриПолученииДанныхНаСервере(). Он дольше в реализации, но позволяет хорошо затюнить виртуальную таблицу и избежать сценария выше. На каждую прокрутку списка получится больше запросов, но они будут быстрее и эффективнее, чем один, но гигантский.