Регулярно слышу тейк: запросом больше, запросом меньше — без разницы. Мол, главное, чтобы запрос был дешевым: не читал лишнего, попадал в индекс и так далее.
Эта точка зрения имеет право на жизнь, однако бездумно пулеметить запросами — опасная затея. Даже если в моменте все выглядит хорошо, в будущем система может слегка поменяться. А потом внешне безобидный патч положит вам прод в пятницу.
Пример из недавней практики. Есть ERP, в которой лежит таблица с этапами оплаты по заказам клиентов. Один из таких этапов — предоплата; пока она не внесена, создать заказ поставщику нельзя.
Технически в заказе поставщику просто хранится ID заказа клиента; если последний заполнен (то есть, заказ поставщику создан под заказ клиента), ERP нужно прочитать этапы оплаты по заказу клиента и понять, можно ли делать закупку.
Звучит элементарно, однако мониторинг показывает: операция тормозит и жрет память, будто в последний раз. Лезем разбираться. Видим примерно такую картинку:
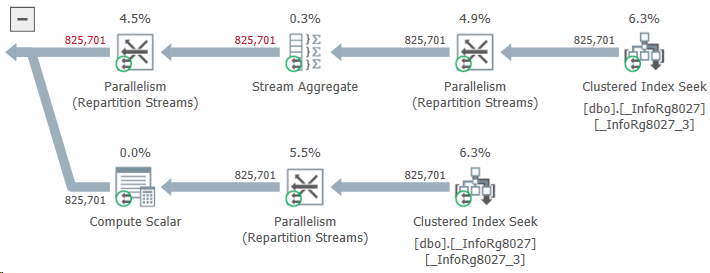
То есть вместо того, чтобы выдернуть два-три этапа оплаты по заказу, ERP читает без малого миллион! Как так?
Опуская детали: проблема рождалась в тех заказах поставщику, которые вообще не были связаны с заказом клиента. Разработчик посчитал, что для них можно не менять логику: ID заказа клиента пустой и запрос не найдет для него этапов оплаты. А значит, получится тот же результат, как если бы запроса вообще не было. А лишний запрос — ну... Запросом больше, запросом меньше... Тоже мне, большое дело.
Оказалось, большое. В таблице этапов оплаты оказались данные не только для заказов клиентов, но и для других видов документов. Поле с ID заказа клиента у них было пустым. В итоге ERP при попытке найти этапы оплаты по пустому ID заказа клиента находила такие записи — и, как видите, немало.
Запрос читал порядка гигабайта данных и помещал во временную таблицу. Гигабайт прочитали, гигабайт записали... История била и по диску, и по буферному кэшу СУБД, и по другим частям системы (вплоть до сети, которой этот гигабайт приходилось гонять туда-сюда без всякой пользы).
В общем, знаете, что я думаю? Если результат запроса известен — наверное, его все-таки не нужно делать.