Заметки
Позднее Ctrl + ↑
Клементина запомнит это
Когда ChatGPT запоминает какую-то деталь диалога на будущее, он рисует над своим ответом плашку "Memory updated". Типа, я понял:
Каждый раз смешно: сразу вспоминается The Walking Dead и мем «Клементина запомнит это» :) В этой игре персонажи, окружающие протагониста, запоминали его решения и это оказывало влияние на их поведение. В том числе и Клементина — девочка, которую главный герой спасает в начале игры.

В игре эта механика была сделана, если честно, так себе, а вот ChatGPT и правда все запоминает. Внимание к деталям такое, что иногда приходится напоминать себе, что разговариваешь с языковой моделью, а не с необыкновенно участливым и очень эрудированным человеком.
Сделать окно дверью
Вчера во время прогулки слушал Be Somebody от Thousand Foot Krutch и неожиданно зацепился за фразу «you made my window a door». Мне эта идиома всегда казалась забавной: блин, врезать дверь вместо окна — это как-то небезопасно звучит. Можно выпасть с десятого этажа, например.
Но песня-то чудесная и совсем не про то! Стало любопытно; пошел копаться, какой смысл вкладывают носители языка.
Оказалось, это про две разные позиции: пассивный наблюдатель и активный участник. То есть, если перед тобой окно — ты лишь смотришь сквозь него на что-то или кого-то. А вот дверь можно открыть и что-то сделать. Так что «when I could only see the floor you made my window a door» — это по смыслу что-то вроде «когда мои руки опустились, ты помогла мне встать».
Кстати, есть ещё одна похожая идиома — «to be a better window than a door». Абстракция здесь та же: если какой-то человек похож на окно, а не на дверь — он никогда не подпускает окружающих близко к себе, делая пассивных наблюдателей даже из очень близких ему людей.
4 августа 2024 английский
Яга
Случайно вспомнил, что полгода назад кто-то из коллег закинул в рабочий чат ссылку на Ягу — будущего (наверное) конкурента JIRA в России. Разработкой, судя по URL, занимаются ребята из Ростелекома. Проснулось любопытство — как оно там, взлетело?
Увы, но похоже, что нет. По крайней мере, на лендинге висит стандартное «оставьте заявку и ждите ответного гудка». Доступна урезанная версия для команд поменбше, но я сейчас не в России, и клик по кнопке «Начать пользоваться» приводит к бану. Ладно, как-нибудь в следующий раз.
Нейминг, конечно, у ребят кликбейтный. Но не уверен, что прям удачный. Например, название «1С», может, и провоцирует натужные шутки (один эс! задница Одина! хахаха!), но если ты гуглишь его — то, скорее, находишь инфу про платформу или хотя бы вендора. А не кучу статей, фанфиков, фанарта и видеоигр, как в случае с Ягой.
И вообще, ассоциации какие-то не те лезут. Избушка на курьих ножках? Выглядит как изначально плохо спроектированное приложение, которое кое-как переделали прямо на проде. Ступа? Костыль? Блин, если смотреть с точки зрения программистов — тут не красные флаги, а алые знамена :)
Ну и я еще, наверное, испорченный, но при слове «Яга» у меня в голове первым делом всплывает не могущественная ведьма из славянского фольклора, а отвратительное пойло из двухтысячных.
И вот баба с ягой уже не быдло, а патриотичная программистка!
― коллега
29 июля 2024 тем временем 1С
Ибрагим
Закатился в курс по анализу систем, который проводят ребята из "Школы сильных программистов". Цели у меня две:
- Во-первых, надо откалиброваться. Много бодаюсь с полдюжиной технических стеков, у которых разный тулсет и понятия о прекрасном. Это, конечно, здорово развивает, но искажает перспективу: меня тянет решать очередную проблему со всяких второстепенных технических штук просто потому, что я это хорошо умею. Между тем, если посмотреть на задачу чуть сверху, подумать и порисовать диаграммы — получается более удачное или, хотя бы, более осмысленное решение. Хочу убедить себя делать так почаще.
- Во-вторых, надо научиться писать внятную документацию для разработчиков. На практике до нее редко доходят руки, а когда доходят — не успеваю поддерживать её в актуальном состоянии. Короче, времени мало, и хочется по крайней мере делать доку как-то так, чтобы читатель живее хватался за мысль.
Сам курс сделан в виде итераций: каждую неделю тебе рассказывают про один и тот же проект, который пытается спроектировать главный герой истории, Ибрагим (это он на лендинге по ссылке выше). Каждую неделю проблем с этим проектом все больше и решения, которые выдумывает Ибрагим, становятся все заковыристее.
Кроме этого, студентам регулярно выдают "домашнюю работу" — другой проект с похожими проблемами. Его нужно проанализировать и спроектировать по-человечески — снова и снова, учитывая новые знания и ограничения, полученные за неделю.
Пока здорово заходит. Главная проблема — нехватка времени: читаю я сравнительно медленно и стараюсь конспектировать самые интересные или просто сложные места. Между тем, материалов в курсе очень много и все интересные, даже если считать только основную часть.
А переходишь к дополнительным ссылкам — вообще хоть святых выноси. Нужно полгода, не меньше. Я старался читать их хотя бы по диагонали, но это оказалось чертовски плохой идеей: кончилось тем, что главный герой курса начал мне мерещиться в уличной рекламе :)

7 июля 2024 тем временем
Сингапурская кукла
Можно ли любить валюту своей страны сильнее, чем жители Саудовской Аравии? Вопрос риторический: уверен, что нет.
Разглядываю сайт их центрального банка. Валюта страны — саудовский риал, и курсы других валют ЦБ устанавливает по отношению к ней. То есть, нет смысла спрашивать с банка курс самого риала. Однако сайт невозмутимо предлагает выбрать его дважды:
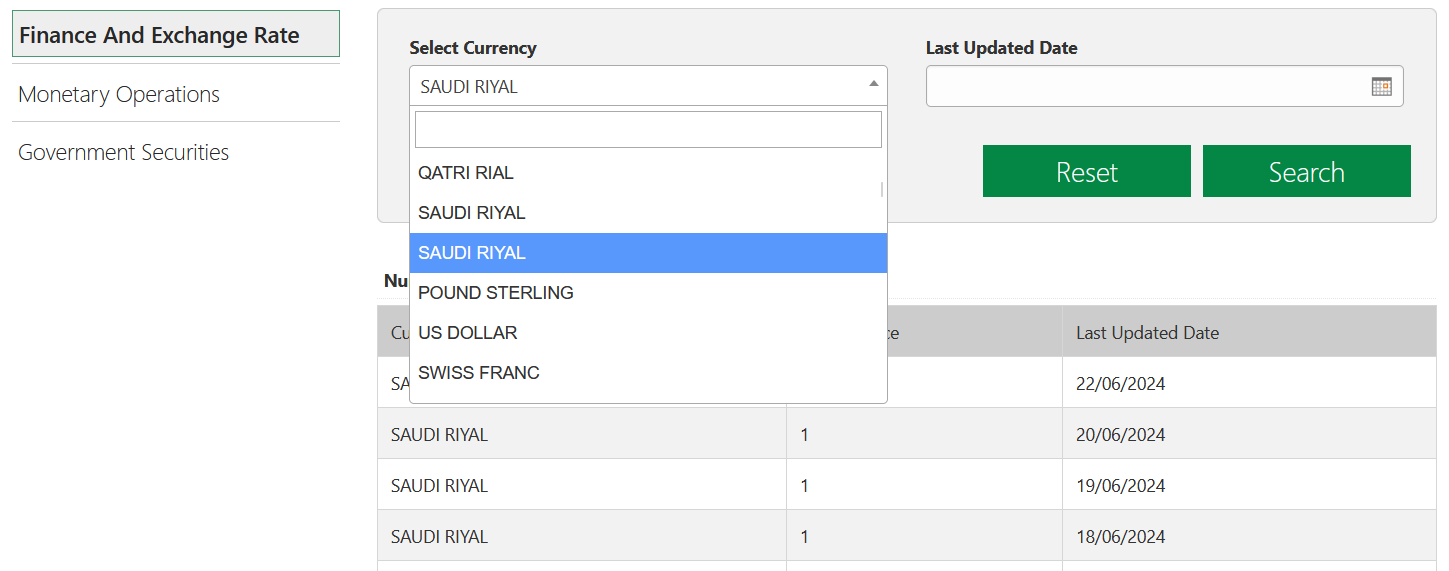
Для справки: первый вариант ломает интерфейс, а второй педантично выдает единицу на любую дату.
Другая забавная деталь: коллеги, кажется, хранят названия валют как строки длиной в 14 символов. Иначе сложно объяснить, почему по их данным в Канаде используется не канадский доллар, а CANADIAN DOLLA, а в Румынии — загадочный NEW ROMANIAN L вместо леи. Впрочем, этим двоим ещё повезло: Сингапур, например, ведёт расчёты в SINGAPORE DOLL.
22 июня 2024 работа
Не уникальные метаданные
В очередной раз столкнулся с противным багом, при котором платформа ломает таблицу с метаданными истории данных.
Внешне он выглядит так: вы обновляете конфигурацию базы, и при попытке реструктуризации выскакивает ошибка "Таблица метаданных истории данных cодержит не уникальные записи, которые должны быть удалены".
При этом платформа не предлагает никакого понятного способа найти такие записи — иди туда, не знаю куда, сделай то, не знаю что.
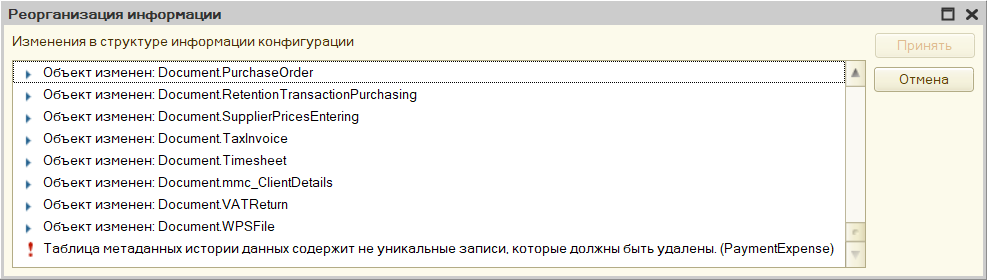
Проблему можно решить, порывшись в базе данных. Таблица, на которую ссылается ошибка — _DataHistoryMetadata. В ней лежат версии метаданных каждого объекта, для которого ведётся история. Это позволяет платформе понимать, какие реквизиты были у объекта на любой момент времени, в течении которого для объекта велась история.
Как это работает? Ну, когда меняется состав реквизитов объекта (например, реквизит в справочнике добавили), платформа запоминает его метаданные: конкретно, добавляет в _DataHistoryMetadata новую запись и сохраняет в ней актуальный список реквизитов объекта, а также номер версии этого списка (например, в при включении истории для объекта сохраняется первая версия метаданных, при добавлении какого-нибудь реквизита — вторая и так далее).
Ещё платформа ставит в созданной записи отметку, что именно эта версия объекта — самая актуальная, после чего снимает этот флаг с той версии, которая была помечена актуальной до этого.
Так вот, проблема в том, что платформа иногда забывает сделать последний шаг и в таблице появляется сразу две версии, помеченные как актуальные. Конфигуратор понимает это, но сделать ничего не может.

Решение вытекает из алгоритма выше: нужно найти конфликтующие версии и отобрать признак актуальности у той, что старше. Лучше использовать запросы: история данных включают, как правило, для кучи объектов и состав реквизитов у них постоянно меняется — в общем, версий в таблице будет столько, что черт ногу сломит.
Если вы тоже столкнулись с этой проблемой и поэтому читаете этот текст — можете воспользоваться запросами, что написал я:
- get-issues.sql проверяет, что проблема есть: ищет версии метаданных, которые одновременно помечены как актуальные.
- fix-issues.sql снимает признак актуальности с тех версий, которые на самом деле устарели.
Оба запроса написаны для Microsoft SQL Server. Если вы используете PostgreSQL, то вот они же для этой СУБД.
Запросы потребуют небольшой адаптации под конкретную базу: в них используется поле _fld626, в котором хранится разделитель данных. В вашей таблице _DataHistoryMetadata это поле может называться иначе, поэтому нужно обновить его имя на актуальное. Ошибиться будет трудно — у таблицы только одно поле с префиксом _fld.
P.S. Напоминаю, что лицензионное соглашение запрещает ковыряться в базе данных в обход средств платформы, так что на такие эксперименты можно идти, только если других вариантов не осталось.
8 июня 2024 1С PostgreSQL MS SQL
Главная проблема UUID
Наткнулся на хороший текст об основной проблеме, которую таскает с собой UUID. Для 1С она тоже актуальна: все ссылочные объекты платформы (элементы справочников, документы и так далее) имеют собственные UUID. Они хранятся в БД, активно используются при поиске и, понятно, обильно индексируются (со всеми вытекающими последствиями).
1С старается компенсировать проблему, создавая последовательные UUID. Пусть не идеально, но в целом эта штука работает и индексы получаются более-менее ровными. Да и вообще в сообществе об этом говорят довольно давно: вот, например, бородатый топик на Мисте (правда, тут диалог быстро перерос в курятник и из шести десятков комментариев от силы полтора — по делу).
P.S. Рассмешила ремарка про вероятность создать в одной базе два одинаковых UUID:
As an aside, for those worried about collisions: you should take up the lottery, since winning the jackpot twice in a row is a much more likely outcome than your system ever generating two identical random 128 bit numbers.
2 июня 2024 1С PostgreSQL
Скриншот со звуком
Недавно в компании родилась идея разделить внутреннюю ERP-шку на несколько независимых частей и организовать между ними обмен данными. Мы обсудили контуры задачи, модель обмена, транспорт, примерно подбились по срокам — в общем, привычная рутина.
Создал под весь этот огород задачу. Названия им мы даем на английском языке, так что вписал первую формулировку, которая пришла в голову.
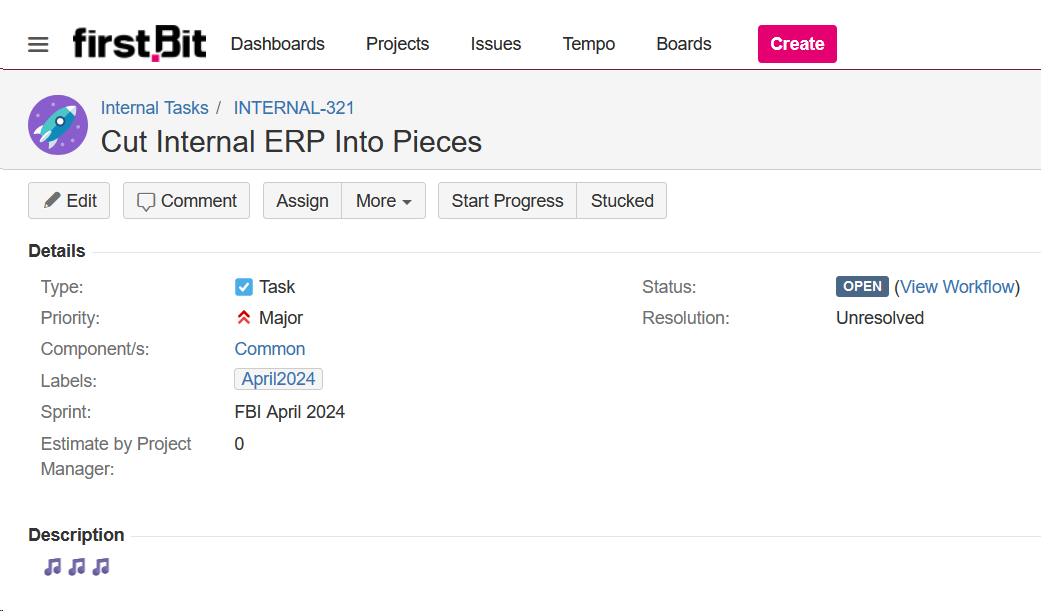
Заголовок вышел со звуком. Ладно, думаю, смешно, но как тогда назвать? Во, пусть будет Distributed Internal ERP. Сокращенно... DIE?
Оставил первый вариант. Long live Papa Roach :)
20 мая 2024 работа тем временем
Таймшит для Обсидиана
Написал ещё один плагин к Obsidian, на этот раз — для ежедневных заметок. Рисует симпатичный отчет: над какими задачами работал, что сделал, сколько времени потратил. Я постарался описать в репозитории, как это работает; буду рад, если кому-то ещё пригодится!
Забавный момент: для примеров в README я использовал номера задач FBI-1, FBI-2 и так далее. Это не отсылка к X-Files или Twin Peaks — просто первое, что пришло мне в голову. Дело в том, что наш внутренний проект по разработке FirstBit ERP называется First Bit Internal, сокращенно — FBI. Основной пул задач, над которыми мы работаем, живёт именно в нём.
Мы-то уже привыкли, но коллег вне компании наши скриншоты из JIRA или SonarQube неизменно веселят. Представили, что вы — агент Купер? А мне и представлять не надо :)
12 мая 2024 готово TypeScript Obsidian работа
Запросом больше, запросом меньше
Регулярно слышу тейк: запросом больше, запросом меньше — без разницы. Мол, главное, чтобы запрос был дешевым: не читал лишнего, попадал в индекс и так далее.
Эта точка зрения имеет право на жизнь, однако бездумно пулеметить запросами — опасная затея. Даже если в моменте все выглядит хорошо, в будущем система может слегка поменяться. А потом внешне безобидный патч положит вам прод в пятницу.
Пример из недавней практики. Есть ERP, в которой лежит таблица с этапами оплаты по заказам клиентов. Один из таких этапов — предоплата; пока она не внесена, создать заказ поставщику нельзя.
Технически в заказе поставщику просто хранится ID заказа клиента; если последний заполнен (то есть, заказ поставщику создан под заказ клиента), ERP нужно прочитать этапы оплаты по заказу клиента и понять, можно ли делать закупку.
Звучит элементарно, однако мониторинг показывает: операция тормозит и жрет память, будто в последний раз. Лезем разбираться. Видим примерно такую картинку:
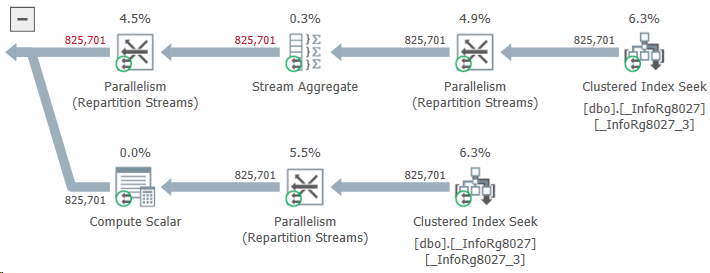
То есть вместо того, чтобы выдернуть два-три этапа оплаты по заказу, ERP читает без малого миллион! Как так?
Опуская детали: проблема рождалась в тех заказах поставщику, которые вообще не были связаны с заказом клиента. Разработчик посчитал, что для них можно не менять логику: ID заказа клиента пустой и запрос не найдет для него этапов оплаты. А значит, получится тот же результат, как если бы запроса вообще не было. А лишний запрос — ну... Запросом больше, запросом меньше... Тоже мне, большое дело.
Оказалось, большое. В таблице этапов оплаты оказались данные не только для заказов клиентов, но и для других видов документов. Поле с ID заказа клиента у них было пустым. В итоге ERP при попытке найти этапы оплаты по пустому ID заказа клиента находила такие записи — и, как видите, немало.
Запрос читал порядка гигабайта данных и помещал во временную таблицу. Гигабайт прочитали, гигабайт записали... История била и по диску, и по буферному кэшу СУБД, и по другим частям системы (вплоть до сети, которой этот гигабайт приходилось гонять туда-сюда без всякой пользы).
В общем, знаете, что я думаю? Если результат запроса известен — наверное, его все-таки не нужно делать.
5 мая 2024 1С оптимизация
Фудиари для Обсидиана
Вслед за первым плагином для Obsidian пару недель назад выкатил второй. Считает КБЖУ (калории, белки, жиры и углеводы) в пище. Помогает не переедать на пустом месте — всё-таки на глаз трудно оценить, сколько слопал за день, и можно ли позволить себе вон тот пончик.
Короче, полезная штука, если вы:
- Толстяк (как я)
- Хотите перестать им быть (как я)
- Ведете заметки в Obsidian (как я) 🙂
На самом деле, программ для этой задачи полным-полно (я перепробовал штук десять). Остался недоволен: либо страшная, либо глючит, либо постоянно пытается всучить ежемесячную подписку. Короче, больше раздражает, чем помогает. Хочется чего-то нативного, встроенного в обычную рутину — и если она оседает в Obsidian, то решение напрашивается само собой.
Установить плагин можно прямо из программы — разработчики его уже одобрили. В остальном всё просто: пишем в ежедневной заметке, что съели и сколько это весило, и в ответ получаем компактную табличку с сортировкой по калориям и числам по белкам, жирам и углеводам.
В репозитории по ссылке выше есть примеры.
14 апреля 2024 готово TypeScript Obsidian
Внешний вид Фастаймера
Завернул отрисовку Фастаймера через выноски: это механика Obsidian, позволяющая превращать обычную цитату в оформленный блок текста, привлекающий внимание читателя. Вы наверняка видели блоки в духе «совет» и «обрати внимание» — вот это и есть выноски.
Подробнее можно прочитать в справке Obsidian.
В общем, теперь таймер принимает разный цвет в зависимости от состояния (активный интервал — голубой, успех — зеленый, провал — красный). Кроме того, я немного уплотнил текст и отточил формулировки:
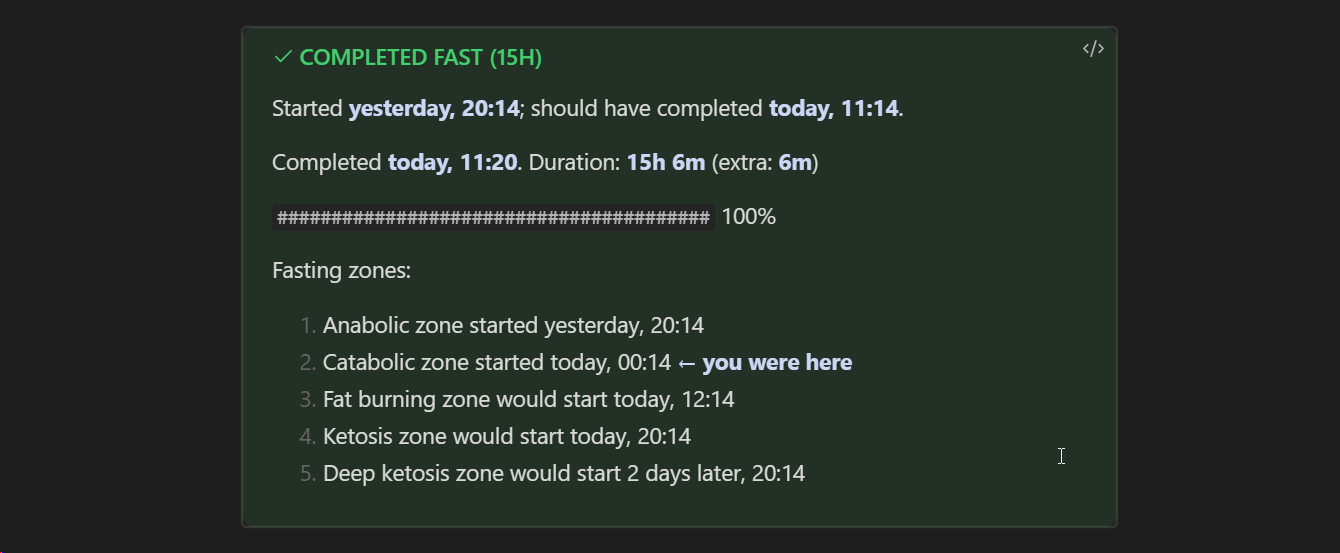
Получилось компактнее и симпатичнее простого блока текста, который я использовал до этого.
9 марта 2024 Obsidian TypeScript
Маленькие радости
Скучаю в очереди на кассу супермаркета: вечер, покупателей уже не очень много, но пожилая кассирша явно устала и не слишком торопится. Стоящий впереди высокий, седой мужчина с роскошной бородой коротает время, изучая стойку с шоколадками рядом с кассой.
Наконец, берет «Сникерс», задумчиво крутит его в руках. Пододвигает себе ещё два и широко, с видимым удовольствием улыбается в усы :)
6 марта 2024 тем временем Грузия
Не только лишь все
Завидной глубины комментарий из документации к методу WriteJSON() XDTOSerializer'а:

Ну да, метод дампит данные в JSON, а не в XML. Так что поспорить сложно, не все типы данных можно упаковать в XML с его помощью (если быть точным — никакие). Если бы дальше не пошла очевидная копипаста из справки к WriteXML() — счёл бы пасхалкой от разработчиков :)
25 февраля 2024 1С
Фастаймер для Обсидиана
Разработчики Obsidian на днях заапрувили один из моих пет-плагинов на TypeScript — Фастаймер, трекер интервального голодания. Он добавляет в хранилище новый блок кода: вводишь в него дату начала окна голодания и получаешь дату завершения, время до этого момента и раскладку по зонам, которые предстоит пройти.
Блок показывает актуальную картину каждый раз, когда Obsidian его отрисовывает — то есть, можно следить за своим прогрессом в реальном времени. Когда окно голодания закончится, можно ввести дату завершения и блок покажет результат: получилось ли выполнить цель, сколько времени сверх плана вы голодали и так далее.
Думаю немного доработать визуальную часть (сейчас всё выводится текстом без какого-либо оформления). А ещё — прикрутить функции расчета статистики, чтобы можно было на ходу рисовать красивые графики в духе Charts и показывать ачивки. У меня была эта механика в реализации этого же приложения на Python, но я вряд ли к ней вернусь — в хранилище Obsidian эту задачу решать проще, чем раскатывать на компьютер дополнительную утилиту.
Короче, зацените плагин! :) В библиотеке Обсидиана его можно найти по имени (Fastimer). Или, при желании, установить вручную из репозитория.
13 февраля 2024 готово TypeScript Obsidian
Do? Do Not?
На одном из проектов у нас есть две общающиеся друг с другом системы: ERP и CRM. Обмен данными сделан по-взрослому: поднят push'n'pull сервер, прописаны подписки на события, подняты REST API и много другой интересной технической обвязки, но я сейчас не про неё.
Среди прочей логики, там так: если в CRM появляется новый контрагент — его данные отправляются в ERP. На днях с этим возникла проблема: один из контрагентов не отправлялся из CRM ну вот вообще никак, сколько его не записывай. Полезли разбираться, подозревая худшее: CRM написана на PHP (ничего личного, просто это не наш технический стек) и там много разного легаси. Выстрелить себе в ногу проще, чем высморкаться.
Однако особенно долго копаться не понадобилось. Открыли страницу контрагента в CRM и увидели, что у него стоит галка «Do Not Export To ERP», которая, собственно, блокирует отправку. Короче, очевидная ошибка какого-то менеджера.
Убираем галку, закрываем тикет?

Это решит проблему с этим конкретным контрагентом, но не причину, по которой она возникла. А она в интерфейсе, конкретно — в названии опции: используется «do not», которого желательно избегать из-за того, что пользователям сложнее правильно считать формулировку. К простому «do» это, кстати, тоже относится.
Программистам часто непросто понять, почему так: мы привыкли мгновенно рассчитывать в уме булевые выражения и вариации в духе «не (не истина)» для нас — обычное дело. А вот люди с другим бэкграундом могут путаться. Совсем чуточку, но иногда и этого достаточно, чтобы в горячке дня воспринять «do not export» как «do export», ткнуть опцию и побежать дальше.
Отсюда выводим правильное решение: переименовать галку. Подойдёт «Disable Export» или «Stop Export». В голову ещё приходит «Prohibit Export», но это скорее про межличностные отношения и вообще, запрет что-то делать не означает, что это что-то не будет сделано :)
14 января 2024 работа английский
Последний мет
Роюсь в коде внешней компоненты 1С, опубликованный разработчиками платформы как пример у себя на сайте. Из хорошего: ну, она компилируется и, если немного допилить — действительно работает.
В остальном хватает bruh moments: например, проект не открывается в современной Visual Studio (нужно указывать CMake вручную). Код довольно небрежный, документации нет, комментариев и оформления по большому счёту тоже. Разработчику без опыта в С++ может быть непросто вкатиться.
Позабавил нейминг:
long CAddInNative::FindMethod(const WCHAR_T* wsMethodName)
{
long plMethodNum = -1;
wchar_t* name = 0;
::convFromShortWchar(&name, wsMethodName);
plMethodNum = findName(g_MethodNames, name, eMethLast);
if (plMethodNum == -1)
plMethodNum = findName(g_MethodNamesRu, name, eMethLast);
delete[] name;
return plMethodNum;
}
Со строк выше на нас смотрит необъяснимая любовь автора кода к сокращениям: вот что ему мешало назвать переменную "eMethodLast", а не "eMethLast"? В конце концов, у нас уже есть "wsMethodName" и "plMethodNum".
Возможно, это такая пасхалка с отсылкой на Breaking Bad. Тогда, конечно, уверенный лайк :)
17 декабря 2023 1С
Пропущенный съезд
Вы когда-нибудь пропускали свой съезд с шоссе? Нужно всего лишь доехать до следующего, чтобы развернуться, но каждый дюйм дороги вызывает отвращение, потому что ты удаляешься от цели.
― Энди Вейер, «Марсианин»
У программистов бывают ровно те же эмоции, когда они долго пилят какую-то систему и внезапно осознают, что один из её компонентов стоит задизайнить иначе. В этот момент рождается технический долг: понимаешь, что именно так и придется поступить, так как это разом закроет несколько проблем.
Однако прямо сейчас, в моменте, не меняется ничего: ты продолжаешь пилить код вокруг того компонента, что есть. Ведь у тебя есть сроки на разработку, и ты профессионал! Нужно всего лишь выпустить релиз, чтобы вернуться к техдолгу, но каждый дюйм написанного кода вызывает отвращение, потому что ты удаляешься от цели.
14 ноября 2023 код с запашком
Бытовой героизм
Поднимал какое-то время назад Swagger для внутренней API-шки. Пока возился — стало понятно, что часть функционала в документацию включать не нужно. Поискал способ, как это сделать без костылей — наткнулся на забавный вопрос на GitHub'е.
Чем забавный? Ну, невольно вспомнил про Мисту. В среде 1С-разработчиков это синоним слова "токсичность": мол, спросишь там что-нибудь — получишь ушат помоев за шиворот вместо ответа. Здесь, конечно, не так всё запущено, но ребята, с завидным упорством ссылающиеся на 14-и страничный мануал, здорово рассмешили.
Одно радует: к концу треда всё же нашёлся отважный повстанец, который просто взял и запостил нужный параметр для декоратора.
Не все герои носят плащи, ей-богу.
Румынская фича
Делаю для нашего клиентского портала функцию восстановления пароля через SMS. Добрался до документации Twilio о поддержке буквенно-цифрового ID отправителя в разных странах; эта фича позволяет отправлять сообщения так, чтобы получатель видел не номер отправителя, а что-то осмысленное (название компании, например).
При этом фича везде зарегулирована по-своему: где-то просто работает, где-то нужна регистрация.
Читаю:
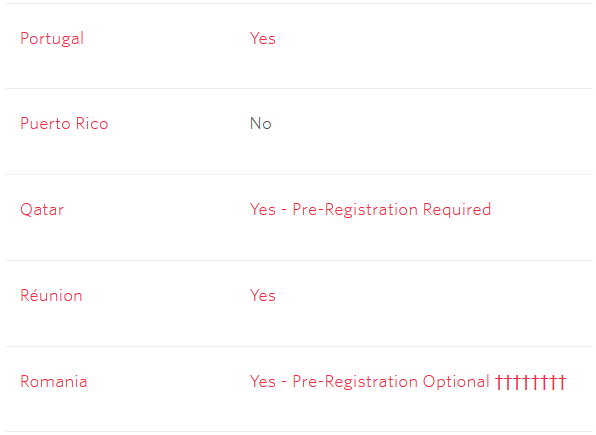
🤔
- Португалия: да
- Пуэрто-Рико: нет
- Катар: да (с регистрацией)
- Реюньон: да
- Румыния: да (с регистрацией) (но бойтесь Дракулы)
Не знаю, как ещё объяснить это кладбище.
UPD: Нашёл разгадку. Могильные кресты означают, что за регистрацию нужно заплатить 700 баксов.
Объяснение про Дракулу мне нравилось больше.
30 августа 2023 тем временем работа
Ранее Ctrl + ↓